Au départ, l’objectif était simple : ajouter deux disques à un pool ZFS raidz1. Pas de migration majeure, juste une extension de stockage. Sauf que la fonctionnalité qui permet ça — raidz_expansion — n’est disponible qu’à partir de ZFS 2.3, lui-même embarqué à partir de Proxmox 9. Et comme le serveur tournait en Proxmox 8.4, la logique était implacable.
Le contexte
Le serveur en question est un HP ProLiant DL360 G6, un vieux de la vielle mais parfait justement pour s’amuser avec proxmox. Il tourne Proxmox VE 8.4 en nœud standalone, avec une VM Proxmox Backup Server. Le stockage est un pool ZFS raidz1 composé de 4 disques 1 To, et deux disques supplémentaires attendaient d’être intégrés depuis un moment.
La raison du délai ? Ben autre chose faire et quand je decide de m’y mettre je decouvre avec effroi que raidz_expansion n’existe tout simplement pas dans les versions précédentes de ZFS. Avant ZFS 2.3, pour ajouter un disque à un raidz existant, il fallait créer un nouveau pool et migrer les données. Laborieux. Depuis ZFS 2.3, c’est natif : on attache le disque, ZFS redistribue les données en arrière-plan, le pool reste en ligne pendant toute l’opération.
Proxmox 9 embarque ZFS 2.3. Il va falloir migrer avant toute extension du ZFS.
Premier obstacle : le contrôleur MegaRAID qui cache les disques
Avant même de parler de Proxmox ou ZFS, il a fallu régler un problème matériel.
Le serveur vient de recevoir 2 nouveaux controlleurs un LSI MegaRAID SAS 9240-4i. Et après le changement, Proxmox ne voyait plus aucun pool ZFS. Résultat d’un zpool import : rien.
root@pve:~# zpool import
# ... silence total
La cause est classique mais piégeuse : le MegaRAID 9240-4i est livré en mode RAID par défaut. Il présente les disques physiques comme des volumes logiques à l’OS, pas comme des disques bruts. ZFS a besoin de voir les disques individuellement pour lire ses métadonnées. En mode RAID hardware, il voit un volume opaque et ne peut rien faire.
La solution passe par le mode JBOD, qui dit au contrôleur de passer les disques en transparence vers l’OS. Via MegaCLI :
# Voir les disques physiques
MegaCli -PDList -aALL | grep -E "Slot|State"
# Activer le JBOD mode global
MegaCli -AdpSetProp EnableJBOD 1 -a0
# Puis passer chaque disque en JBOD
MegaCli -PDMakeJBOD -PhysDrv[E:S] -a0
Alors les controlleurs 9240 proposent aussi un GUI auquel on peu acceder en faisant CTRL + H pendant les messages post lors du demarrage du serveur mais j’ai oublié de faire la photo desolé
Après reboot, les disques apparaissent comme des devices individuels, et ZFS retrouve ses métadonnées instantanément :
root@pve:~# zpool import
pool: DATA-Raidz1
state: ONLINE
L’avantage de ZFS sur les systèmes de fichiers classiques : chaque disque embarque les métadonnées du pool dans ses propres labels. Peu importe le chemin (/dev/sdX ou autre), peu importe le contrôleur, ZFS scanne et retrouve ses petits tout seul — à condition qu’on lui présente les disques bruts.
Deuxième détour : les erreurs DMAR
Au reboot suivant, des erreurs apparaissent dans les logs :
dmar: error dma pte for vpfn ...
Cause : le ProLiant G6 a VT-d activé dans le BIOS, et le vieux MegaRAID SAS ne coopère pas bien avec IOMMU. Ce n’est pas cosmétique — ce type d’erreur peut causer des problèmes de corruption ZFS lors des scrubs, via des erreurs CKSUM.
Solution : désactiver VT-d dans le BIOS. À ne pas confondre avec VT-x, qui est la virtualisation CPU et doit rester activé. VT-d gère le passthrough PCI — utile uniquement si on passe un device physique directement à une VM. Dans ce cas précis, avec le MegaRAID en JBOD, VT-d ne sert à rien et crée des problèmes.
Sur un ProLiant G6, l’option est dans : System Options → Processor Options → Intel VT-d. Désactivation, reboot, plus d’erreurs DMAR.
Préparation de la migration Proxmox
État des lieux
root@pve:~# pveversion
pve-manager/8.4.19/a68fb383814bb1e6 (running kernel: 6.8.12-29-pve)
root@pve:~# pve8to9 --full
Le checklist pve8to9 remonte 4 warnings, 0 failures :
- 1 VM en cours d’exécution — le PBS, qu’on arrêtera avant l’upgrade
- systemd-timesyncd — à remplacer par chrony
- systemd-boot installé sur legacy-boot — à supprimer
- intel-microcode manquant — à installer
Résolution des warnings
NTP — remplacement par chrony :
apt install chrony
L’installation retire automatiquement systemd-timesyncd. On configure chrony sur les serveurs NTP internes :
cat > /etc/chrony/chrony.conf << 'EOF'
server 192.168.x.x iburst prefer
server 192.168.x.x iburst
driftfile /var/lib/chrony/chrony.drift
makestep 1.0 3
rtcsync
EOF
systemctl enable --now chrony
chronyc sources
Nettoyage systemd-boot :
apt remove systemd-boot
Intel microcode :
# Ajouter non-free-firmware aux sources
sed -i 's/bookworm main contrib/bookworm main contrib non-free-firmware/' /etc/apt/sources.list
apt update && apt install intel-microcode
Nettoyage des anciens kernels :
apt autoremove
Point critique : épingler les interfaces réseau
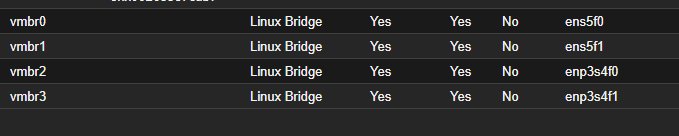
C’est le point le plus important avant toute migration majeure sur un nœud distant ou en production. Le kernel 6.14 embarqué dans Proxmox 9 peut renommer les interfaces réseau — ens5f0 peut devenir enp8s0f0 après le reboot. Si ça arrive, la config réseau ne correspond plus aux interfaces réelles et le nœud est inaccessible à distance.
On vérifie les interfaces et leurs MACs :
ip link show
cat /sys/class/net/ens5f0/address
cat /sys/class/net/ens5f1/address
Et on crée des règles udev pour épingler les noms par adresse MAC :
cat > /etc/udev/rules.d/70-persistent-net.rules << 'EOF'
SUBSYSTEM=="net", ACTION=="add", ATTR{address}=="xx:xx:xx:xx:xx:xx", NAME="ens5f0"
SUBSYSTEM=="net", ACTION=="add", ATTR{address}=="xx:xx:xx:xx:xx:xx", NAME="ens5f1"
SUBSYSTEM=="net", ACTION=="add", ATTR{address}=="xx:xx:xx:xx:xx:xx", NAME="enp3s4f0"
SUBSYSTEM=="net", ACTION=="add", ATTR{address}=="xx:xx:xx:xx:xx:xx", NAME="enp3s4f1"
EOF
Après le reboot post-migration, toutes les interfaces auront exactement les mêmes noms qu’avant. Les bridges Proxmox (vmbr0, vmbr1…) s’y retrouveront sans aucune modification.
La migration
La VM PBS est stoppée. On ouvre une session tmux — obligatoire pour une migration en SSH, le processus doit survivre à une déconnexion :
tmux new -s upgrade
Mise à jour des repos bookworm → trixie :
sed -i 's/bookworm/trixie/g' /etc/apt/sources.list
sed -i 's/bookworm/trixie/g' /etc/apt/sources.list.d/*.list
Vérification avant de lancer :
cat /etc/apt/sources.list
# deb http://ftp.fr.debian.org/debian trixie main contrib non-free-firmware
# deb http://ftp.fr.debian.org/debian trixie-updates main contrib non-free-firmware
# deb http://security.debian.org trixie-security main contrib non-free-firmware
# deb http://download.proxmox.com/debian/pve trixie pve-no-subscription
Lancement :
apt update && apt full-upgrade
Sur les questions interactives de conf : garder ses propres fichiers (N) sauf pour les fichiers qu’on n’a pas modifiés. En particulier, chrony.conf qu’on vient de configurer — répondre N pour conserver la config NTP interne.
Après le full-upgrade, on vérifie avant de rebooter :
root@pve:~# pveversion
pve-manager/9.2.3/d0fde103346cf89a (running kernel: 6.8.12-29-pve)
PVE 9.2.3 installé. Le kernel affiché est encore l’ancien — le nouveau sera chargé au reboot.
reboot
Résultat post-migration
root@pve:~# uname -r
7.0.6-2-pve
root@pve:~# zpool status DATA-Raidz1
pool: DATA-Raidz1
state: ONLINE
scan: scrub repaired 0B in 00:09:59 with 0 errors
config:
NAME STATE READ WRITE CKSUM
DATA-Raidz1 ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
ata-TOSHIBA_... ONLINE 0 0 0
ata-TOSHIBA_... ONLINE 0 0 0
ata-TOSHIBA_... ONLINE 0 0 0
ata-ST1000LM0... ONLINE 0 0 0

Kernel 7.0.6-2-pve, pool ZFS intact, interfaces réseau inchangées. La VM PBS redémarre normalement.
ZFS pool upgrade
Avant d’étendre le pool, on active les nouvelles features ZFS 2.3 :
root@pve:~# zpool upgrade DATA-Raidz1
Enabled the following features on 'DATA-Raidz1':
redaction_list_spill
raidz_expansion ← c'est celle-là qui nous intéresse
fast_dedup
longname
large_microzap
block_cloning_endian
physical_rewrite
raidz_expansion est activée. On peut maintenant ajouter des disques au raidz1 sans reconstruire le pool.
Extension du raidz1
Préparation des disques
Les deux nouveaux disques ont été vérifiés (lsblk, SMART passé), puis wipés proprement :
wipefs -a /dev/sdb
wipefs -a /dev/sdc
sgdisk --zap-all /dev/sdb
sgdisk --zap-all /dev/sdc
Scrub avant extension
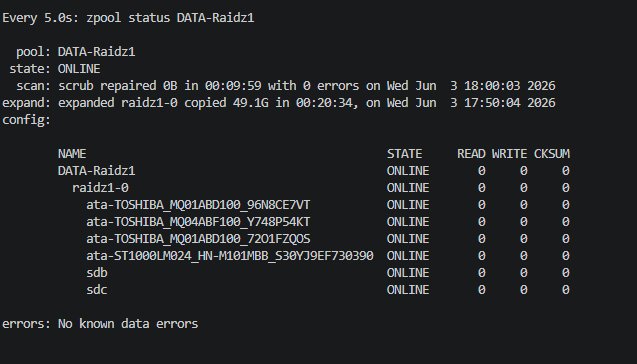
Pas question d’étendre un pool sans vérifier son intégrité d’abord :
zpool scrub DATA-Raidz1
watch -n5 zpool status DATA-Raidz1
Résultat : scrub repaired 0B in 00:09:59 with 0 errors. Pool sain, on peut y aller.
Ajout des disques
zpool attach DATA-Raidz1 raidz1-0 /dev/sdb
La redistribution démarre immédiatement :
expand: expansion of raidz1-0 in progress since ...
1.98G / 49.2G copied at 102M/s, 4.03% done, 00:07:55 to go
config:
raidz1-0 ONLINE
ata-TOSHIBA... ONLINE
ata-TOSHIBA... ONLINE
ata-TOSHIBA... ONLINE
ata-ST1000LM.. ONLINE
sdb ONLINE ← nouveau disque intégré
ZFS redistribue les données existantes sur le nouveau disque pendant que le pool reste en ligne et accessible. Aucun impact sur la VM PBS qui tourne dessus.
Une fois la première expansion terminée, on ajoute le second disque :
zpool attach DATA-Raidz1 raidz1-0 /dev/sdc
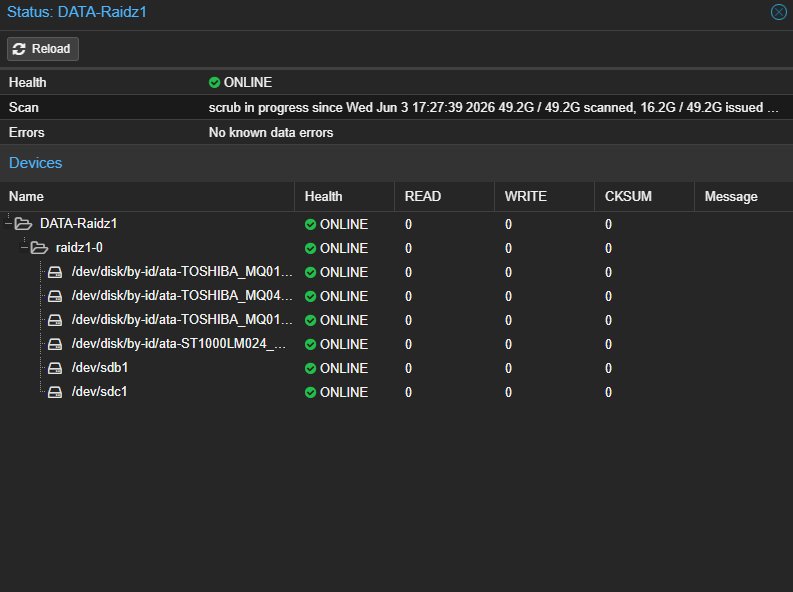
Résultat final
pool: DATA-Raidz1
state: ONLINE
expand: expanded raidz1-0 copied 49.1G in 00:20:34
config:
NAME STATE
DATA-Raidz1 ONLINE
raidz1-0 ONLINE
ata-TOSHIBA_... ONLINE
ata-TOSHIBA_... ONLINE
ata-TOSHIBA_... ONLINE
ata-ST1000LM0... ONLINE
sdb ONLINE
sdc ONLINE

6 To utilisables, raidz1 à 6 disques, 0 erreurs. Le pool est passé de ~3 To utiles à ~5 To utiles, en live, sans reconstruire quoi que ce soit.
Ce qu’il faut retenir
raidz_expansion change fondamentalement la gestion du stockage ZFS. Avant, ajouter un disque à un raidz existant n’était pas possible — il fallait créer un nouveau pool, migrer, reconstruire. C’était la principale limite de ZFS comparé à d’autres solutions. Cette contrainte n’existe plus à partir de ZFS 2.3.
La migration Proxmox 8 → 9 est propre si on prend le temps de faire le checklist pve8to9 --full et de traiter les warnings avant de lancer. L’upgrade lui-même est standard — repos, apt full-upgrade, reboot. Pas de surprise.
Les interfaces réseau sont le seul vrai piège. Les épingler par MAC avec une règle udev avant la migration prend 5 minutes et évite potentiellement de se retrouver sans accès sur un nœud distant.
Le contrôleur MegaRAID en mode RAID cache les disques à ZFS. Ce n’est pas un bug, c’est le comportement par design d’un contrôleur RAID hardware. La solution est le mode JBOD — passer les disques en transparence vers l’OS. À savoir si on récupère du matos serveur HP/Dell/IBM avec ce type de contrôleur.
Testé sur HP ProLiant DL360 G6, Proxmox VE 9.2.3, kernel 7.0.6-2-pve, ZFS 2.3, LSI MegaRAID SAS 9240-4i.